借过同事的一本《go语言并发之道》一直都没有去阅读。我是非常懒惰的,开一篇笔记,督促自己将本书阅读完成。主要是抓举一些概念,然后就是理解如何组织代码。
O’Reily 奥莱利 出版社,原书名:《Concurrency in Go》,IBSN 978-7-5198-2494-5. 图书馆编码 TP312
0. 前言
本书一共6章节。
作者罗列golang中的好处,简洁、编译快速、运行稳定、支持鸭子类型(duck typing)。最重要的还是语言级原生支持并发。
作者在过去几年使用golang做项目,出于在社区里面没有Golang并发编程的综合指南,决定编写这本书。
本书的读者对象
本书不会讲解Golang基础语法。最好能了解过其他语言的并发。
讨论的并发逻辑:常见并发陷阱,golang并发设计原则,golang并发原语中的基础语法,常见并发模式,并发模式的设计,各种工具使用。
各章节的简介
- 并发概述
Global_Keys
从广泛的历史视角说明并发的重要性,讨论并发中的一些难点。简要介绍golang如何解决这些问题。
如果知道并发相关知识,可以跳过本章;
- 对你的代码建模:通讯顺序进程
论述推动golang设计的一些激励因素。
- golang并发组件
介绍golang并发原语。介绍控制内存访问同步sync包。
通过golang代码并发片段,与其他语言的并发模型对比。有助于完全理解golang的并发实现。
- Golang的并发模式
讨论使用Golang原语函数构建合理的模式。
对于已经开始写golang的并发代码,这种是有些用处。
- 大规模并发
将组合并发模式,设计合理的模型,应用于大型程序、服务和分布式系统中。
- goroutine和golang运行时
描述golang中的goroutine如何调度。想了解golang虚拟机的人可以阅读这一章节。
1. 并发概述
1.1. 并发的重要性
摩尔定理增速会放缓。
Amdahl定律(Gene Amdahl):并行计算中的加速比是用并行前的执行速度和并行后的执行速度之比来表示的,它表示了在并行化之后的效率提升情况。
阿姆达尔定律是固定负载(计算总量不变时)时的量化标准。可用公式:(Ws+Wp)/(Ws+(Wp/p))来表示。式中Ws,Wp分别表示问题规模的串行分量(问题中不能并行化的那一部分)和并行分量,p表示处理器数量。
当p趋近于无穷大,这意味着无论我们如何增大处理器数目,加速比是无法高于这个数的。
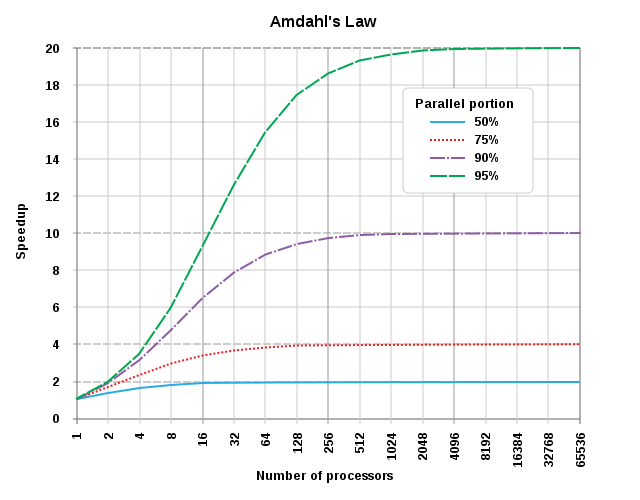
将问题W->拆分成Ws,Wp两类,也只有Wp能支持被多核优化,产生收益。
1.2. 并发难点
并发代码难写,但是有迹可循。每个人遇到的问题其实都能被归纳总结的。
1.2.1. 竞争条件
本应该按照顺序执行的代码,但是分配到不同的并发的处理里面,编写者如果还认为是顺序执行,那就会出现难以预料的结果。
1.2.2. 原子性
搞清楚上下文概念。
i++
这句话一共分为三步骤:
检索i的值
增加i的值
存储i的值
三个步骤都是原子操作,但是组合起来不一定是原子操作。让组合的这句话能原子操作,取决于这段代码跑在什么上下文中。比如上下文暴漏给多个goroutine就不会是原子操作,而如果只有一个goroutine运行它,那就是原子操作。如果某个操作时原子操作,那就意味着暴漏给多个goroutine跑,也是安全的。
而大多数编写的语句都不是原子操作。在引入并发的时候,如何引入强制保持原子性,粒度如何确定就是考虑的问题。
1.2.3. 内存访问同步
在不同goroutine中访问相同一块内存,可以通过使用 sync.Mutex 来做一个访问的独占。
临界区是否操作过于频繁;
临界区设计得有多大;
1.2.4. 死锁、活锁和饥饿
1. 死锁(deadlock)
死锁至少要出现两把锁;
两把锁调用之间需要间隔一点点时间;
在锁定的顺序两个操作一定是反序的;
2. 活锁(livelock)
活锁指的是任务或者执行者没有被阻塞,由于某些条件没有满足,导致一直重复尝试—失败—尝试—失败的过程。处于活锁的实体是在不断的改变状态,活锁有可能自行解开。活锁可以认为是一种特殊的饥饿。
生活中的典型例子: 两个人在窄路相遇,同时向一个方向避让,然后又向另一个方向避让,如此反复。
两个线程,都拿到一份资源,再互相询问需要对方的资源,询问失败之后,将放弃自己的资源,转而使用反方向来尝试,这样两个线程就会刚好旋转起来。而且两个线程都无法执行任何的逻辑。
3. 饥饿(hunger)
贪婪的work抢占共享锁以完成整个工作循环,而和平的work则试图只在需要使用的时候才锁定。相同的时间间隔内,和平的work比贪婪的work少处理一半的工作量。
贪婪的work不必要扩大对临界区持有时间,并阻止了和平的work高效工作。
可以通过记录进程速度是否达到预期,检测某个进程是否饥饿。
饥饿会导致程序表现低效。
1.2.5. 确定并发安全
在编写函数的时候,需要对函数做一些注解,提醒使用者需要考虑以下问题:
- 谁负责并发?
- 如何利用并发原语解决这个问题的?
- 谁负责同步?
1.2.6. 面对复杂性的简单性
golang的gc在1.8版本开始,gc暂停一般都是 10~100μs
2.对你的代码建模:通信顺序进程
并发于并行的区别
宣讲概念,容易让人觉得好为人师,矫情的不谦逊。
Erlang作者Joe Armstrong举例子:
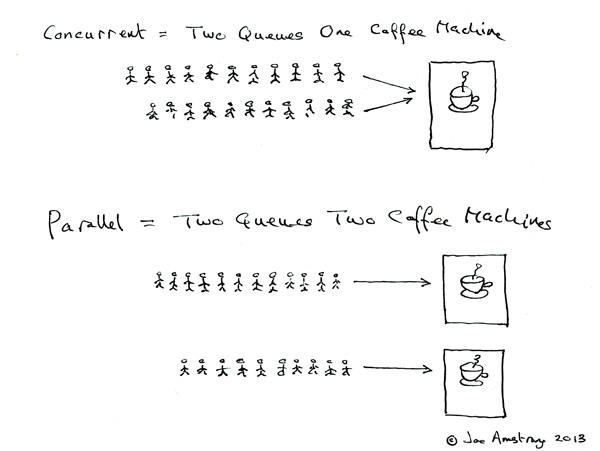
Concurrent
Two queues and one coffee machine.
Parallel
Two queues and two coffee machines.
什么是CSP
communicating sequential processes(通讯顺序进程)。
CSP 并发模型是上个世纪七十年代提出的,用于描述两个独立的并发实体通过共享 channel(管道)进行通信的并发模型。
Go语言就是借用 CSP 并发模型的一些概念为之实现并发的,但是Go语言并没有完全实现了 CSP 并发模型的所有理论,仅仅是实现了 process 和 channel 这两个概念。
process 就是Go语言中的 goroutine,每个 goroutine 之间是通过 channel 通讯来实现数据共享。
Go语言的并发哲学
分辨使用传统锁、channel;
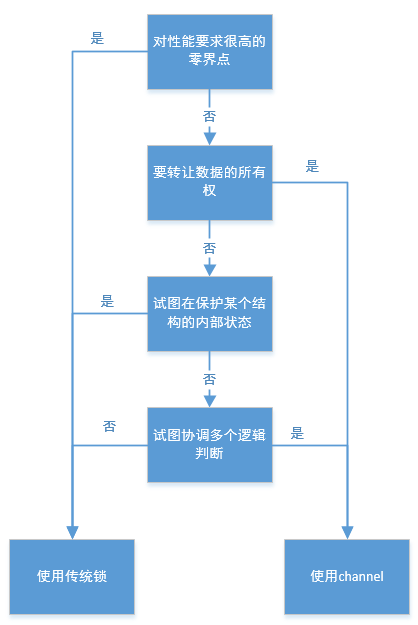
总结:追求简洁,尽量使用channel,并且认为gorountine的使用是没有成本的。
3.Go语言并发组件
goroutine
开启一个golang的协程。作者8G内存的机器,理论上可以创建数百万个goroutine。而且协程切换上下文的时候,成本比较低。
sync包
WaitGroup
可以把它当作线程安全的计数器。Add函数增加计数,Done函数减少计数,Wait函数阻塞,直到计数为0.
1 | var wg sync.WaitGroup |
互斥锁和读写锁
互斥锁用于保护临界区资源
1 | var lock sync.Mutex |
读写锁
1 | var m = sync.RWMutex |
cond
1 | var locker = new(sync.Mutex) |
once
让一个操作只调用一次,就可以使用这个方式来制作。
1 | package main |
常用于制作单例的情况。具体写法:
1 | // 编译命令: |
池
池是对于Pool模式的一种并发安全实现。
对外提供Get方法,如果发现池子里面没有空闲的元素,将会新建一个元素出来。
当使用完成了之后,将会需要调用Put方法将内存归还。
在构建池的时候,需要提供给它一个构造元素的函数。这个函数是线程安全的。
使用场景是这些东西是需要被多个线程共用,而且需求的东西是非常同质化,需要考虑的事情就是new出来,初始化的成本。打个比方:如果需要新建一个db的连接,今后其他的进程还需要使用,这样的情况使用Pool。如果找程序申请一段边长的内存块,那就最好使用new直接搞定。
需要注意的点:
- 当实例化sync.Pool,使用new方法创建一个成员变量,在调用时是线程安全的。
- 当你收到了一个来自Get的实例时,不要对所接受的对象的状态做任何的假设。
- 当你用完了一个Pool中取出来的对象时,一定要调用Put,否则,Pool无法复用这个实例。
- Pool内的分布必须大致均匀。
channel
channel是由Hoare的CSP派生出来的同步原语之一。
channel通常使用Stream来命名这种变量。
1 | var dataStream chan interface{} |
上述的例子是构建了一个双向链表,recvChan和sendChan是为了约束数据的流向,防止在生产者场景下读取了数据。
channel里面读取数据的写法如下:
1 | salutation,ok := <-stringStream |
当channel被关闭了,返回的ok也是失败的。
| 操作 | Channel状态 | 结果 |
|---|---|---|
| Read | nil | 阻塞 |
| 打开且非空 | 输出值 | |
| 关闭的 | <默认值>,false | |
| 只读 | 编译报错 | |
| Write | nil | 阻塞 |
| 打开的但填满 | 阻塞 | |
| 打开,但不满 | 写入值 | |
| 关闭的 | panic | |
| 只读 | 编译报错 | |
| close | nil | panic |
| 打开且非空 | 关闭channel;读取成功,直到通道耗尽,然后读取产生值的默认值 | |
| 打开但空 | 关闭channel;读到生产者的默认值 | |
| 关闭的 | panic | |
| 只读 | 编译报错 |
如果关闭了channel,其实还是会将里面的内容都读取出来的。
1 | var stringStream chan string |
对于channel来说,生产者负责发送数据,并且负责销毁。消费者只负责读取,当无法读取的时候,就说明关闭了。
channel是goroutine的黏合剂
select语句
select是将channel绑定到一块的黏合剂。
select将会选择在其语句段内的某个可工作的通道工作一次。
GOMAXPROCES控制
1 | runtime.GOMAXPROCS(runtime.NumCPU()) |
在1.5之前版本,这个值都是设置成1。后面的版本好像都是已经按照cpu个数来决定多少个线程。2
4.Go语言的并发模型
本章主要是使用3章节中学习到的原语,构建模型出来。
约束
使用词法阅书将channel从生产者传给消费者的时候,只给只读的接口。
for-select循环
按照类似这种结构来组织代码
1 |
|
防止goroutine泄露
goroutine是存在泄露风险,且会造成内存增长。
goroutine有3中情况下种植
完成工作。
由于不可恢复的错误,造成不能工作。
当它被告知需要关闭。
设计原则就是谁创建channel,谁负责将channel关闭。
or-channel
将一个或多个完成的channel合并到一个完成channel,任何channel关闭时自己也关闭。
1 |
|
这样就能将多个channel的结束,合并到一个channel中,任意一个channel结束了就结束。
后续使用”context包”也能做这个事情。
错误处理
错误处理核心问题是“谁负责处理错误”?
谁有全景呈现问题的完整信息,就交付给谁来发起对于错误的报告。
pipeline
不要编写大函数,看待程序应该从两个方面来看待:1.流程;2.处理细节。
构建pipeline的最佳实践
代码中使用了之前防止goroutine泄露写法,防止goroutine无法正常退出。
使用pipeline封装每个stage的处理,可以方便让其能分离出多端独立的逻辑来,然后就能做一些并发的事务了。并且这样做是比较安全的。
一些便利的生成器
这章节的实例也是编写了两个stage来处理生成器,一个负责发生随机字符,另一个控制需要拿多少个。
本章还通过对比测试,其实在多核的时候,并行计算将会更加快速。
扇入,扇出
fan-out,fan-in技术。
本章节其实讨论的问题就是,如何处理多个stage里面不能畅快的跑的问题。
扇入其实就是多个流汇成一个流来处理。
扇出就是将一个流分派给多个流来处理了。
一个处理的pipeline,中间有很重的处理过程,这样只能拓宽这个处理的stage,而负载轻的可以使用少量的stage来处理。
注意:
如果结果到达的顺序不重要,循环独立运行性很重要。
or-done-channel
用于处理已经发起了退出操作,但是channel的数据需要处理完。普通写法比较直观,但是最好还是将代码封装出来,返回一个输出式的channel,外层处理逻辑者比较好写。
tee-channel
类似Unix系统中的tee函数,输入的内容可以在屏幕上输出,并且也输出到一些设定好的文件里面。这种模式其实就是将一份数据并发的分配给两个channel,然后出发后续他们的处理。
桥接channel模式
需要从这个结构里面将其中的channel拿出来,直接写逻辑。使用这个模式就式为了完成这项工作。
1 | <- chan <- chan interface{} |
里面也使用了orDone方式读取 <- chan interface{}
队列排队
有时候,在队列没有准备好的时候,就开始接受请求很有用,这种情况叫做队列。
队列的真正用途是将stage分离,以便一个stage的运行时间不会影响另一个stage的运行时间。以这种方式解耦stage,然后级联以改变整个系统的运行时行为。
这里文中举了个例子,写文件io的,先大量的调用bufio.Writer将内容写入到缓冲区,直到累积到一定程度开始写入硬盘。这个速度提升大概有3倍。但是这样有一些让内存消耗大一些。
利特尔法则
- L = 系统中平均负载数。
- $\lambda$ = 负载的平均到达率。
- W = 负载在系统中花费的平均时间。
L = $\lambda W$
这个等式应用于稳定系统,稳定系统的定义就是输入管道的速率和输出的速率相等。
$nL = \lambda nW$
$L = \lambda \sum_{i=1}^{\infty} Wi$
通过利特尔法则,我们已经证明了队列不会有助于减少在系统中所花费的时间。你的管道只会和最慢的stage一样快。
利特尔法则无法预知处理请求的失败。
队列可能会很有用,但是它是复杂的,作者建议作为最后的优化手段。
context包
由于某种原因(超时,或者强制退出)我们希望中止这个goroutine的计算任务,那么就用得到这个Context了。
Context 的调用应该是链式的,通过WithCancel,WithDeadline,WithTimeout或WithValue派生出新的 Context。当父 Context 被取消时,其派生的所有 Context 都将取消。
通过context.WithXXX都将返回新的 Context 和 CancelFunc。调用 CancelFunc 将取消子代,移除父代对子代的引用,并且停止所有定时器。未能调用 CancelFunc 将泄漏子代,直到父代被取消或定时器触发。go vet工具检查所有流程控制路径上使用 CancelFuncs。
创建context的时候,需要可能需要使用这两个接口。
1 | // 一般用于根context创建 |
创建的时候,Cancel/Deadline/Timeout/Value这四类。
WithTimeout和WithDeadline没有什么差别,就是区分一下输入参数。
小结
模式其实就是抽象出运行的模型,将具体逻辑从运行流程模型中分离出来。这样写逻辑的人只需要按照这个里面的范式来制作内容。
分析一次错误的代码,而且是使用go vet来分析的。
1 | // > go vet ./... |
5.大规模并发
异常传递
在并发系统,特别是分布式系统中,可能会出现难于理解的错误。需要在制作的时候就考虑:如何将这些错误通过分布式系统传递出来,如何将错误呈现给使用者。
呈现异常关键信息:
- 发生了什么;
- 发生的时间、什么位置(调用堆栈-debug.Stack());
- 对用户友好的信息(最好文本方式,而且是一行);
- 告诉用户如何获得更多信息(可以考虑将相关的聚合信息提供出来);
超时和取消
为什么要存在超时呢?
- 系统饱和
- 陈旧数据
数据有窗口期,如果事先知道时间可以使用context.WithTimeout/context.WithDeadline。如果不知道,可以采取 context.WithCancel
1 | ctx, cancel := context.WithCancel(context.Background()) |
- 试图防止死锁
尝试等待一段时间,如果没有将会解开锁定,从而使死锁变成活锁。
并发进程可能被取消的原因
- 超时
- 用户干预
- 父进程取消
- 复制请求(第5章专门论述)
具体可以查看P184的 图5-1,图5-2;
描述了当请求复制请求的情况。
第一种情况建议在下游goroutine接受第一个处理结果,或者最后一个处理结果。
向父goroutine确认权限,是stage A做完事情,还需要找发生器确认授权,然后才能写入stage B。在实际开发中很少这么来处理,原因来自于这样编写非常复杂。
心跳
心跳分类
- 工作间隔时间心跳
- 工作单元开始时心跳
对于任何长时间运行或者需要被测试的goroutine,作者强烈建议使用这个模式。
复制请求
程序处理http请求的时候,可以将这个分配给多个进程、程序或者服务器。优点是更快的拿到结果,缺点是需要维护很多实例,而且消耗更多资源。
速率限制
用于控制http请求时候,不能无限制的对外提供请求资源。否则会容易被攻击。DDoS—分布式拒绝服务攻击。
即使是正常用户,如果用户足够多,也会出现负载异常,造成死亡螺旋。
go语言限速是基于令牌桶算法。
原理:
构造令牌桶,桶有5的深度;
每次需要做事情的时候,需要从桶里面拿到令牌,否则就需要再次尝试;
当用完我们多少时间内补充令牌,有点类似CD;
治愈以常的goroutine
长期运行的后台程序中,经常有那种长时间运行的goroutine。处于阻塞状态,等待某个数据到达,唤醒它们。需要建立机制监控是否处在健康状态。万一出问题的时候,还需要建立机制能重启。
Erlang语言里面有那种监控树 supervisor 也有类似模式。其实最好是能在golang语言本身上构建这样的体系。
小结
本章介绍的方法用于保持系统的稳定和易于理解。
6 goroutine和Go语言运行时
工作窃取
Go语言将会为你调度多个goroutine在不同的系统线程上运行,算法就被称为工作窃取策略。
初步方案是N个处理器,X个任务会被公平调度策略中,每个处理器都获得X/N个任务。但是这样会出现一些问题,比如某项任务比较重,造成其他的CPU会空闲。而且如果任务1依赖于任务4的输出,而它们被分配到不同的P里面,也会造成P的阻塞。
解决办法是创建一个集中队列,让处理器都共享。
工作窃取算法原则:
- 在fork点,将任务添加到与线程关联的双端队列的尾部。
- 如果线程空闲,则选择一个随机线程,从它的关联双端队列头部窃取工作。
- 如果在未准备好的join点(即与其同步的goroutine还没有完成),则将工作从线程的双端队列尾部出战。
- 如果线程的双端队列是空的,则:
a. 暂停加入
b. 从随机线程关联的双端队列中窃取工作。
窃取任务还是续体
go语言中,goroutine就是任务;
在goroutine之后的一切都被称为续体。
续体窃取被认为优于任务窃取,最好是对续体而不是goroutine进行队列。
向开发者展示所有这些信息
在开发过程中其实很简单的使用了go func,其背后有非常复杂的调度算法。
尾声
先学习基本用法,之后再来谈模式,然后是底层运行的原理。
参考
- [1] 本书源码下载地址
- [2] 源码的github地址
- [3] erlang作者谈论并发和并行
- [4] 通讯顺序进程
- [5] 在线LaTex工具
- [6] 深入理解Golang之context
- [7] 快速掌握 Golang context 包
- [8] golang中Context的使用场景
- [9] go vet工具
- [10] GO语言并发之道读书笔记