简介
分析Blob和varbinary;
收集关于MySQL和MariaDB相关差异
Blob varbinary差异
引用自stackoverflow的简单说明,原文参考[1]:
VARBINARY在MySQL 5.0.2及以下版本上被绑定为255字节,在5.0.3及以上版本上被绑定为65kB。BLOB绑定到65kB。最后,VARBINARY实际上与BLOB是一样的(从可以存储什么的角度来看),除非您想保持与“旧”版本MySQL的兼容性。MySQL文档说:
在大多数情况下,您可以将BLOB列视为VARBINARY列,它可以任意大。
golang中如果直接使用byte[],将会生成longblob。Binary和VARCHAR的区别在于将不再需要指定字符集。varbinary类型最大数据存储是2^16-1,其实这个数字就是16位的最大数字—65535。计算下来刚好是65K。其实blob和varbinary非常像。
Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. You have to change some columns to TEXT or BLOBs
row size大概是半个pages的大小,当行里面的数据超出了这个数值,将会出现这样的报错。
mysql官方对于row-size-limits链接,innodb-row-format链接
使用varbinary的时候,将会消耗表的行的空间,blob字段也会消耗一点,但是不大( 9 to 12 bytes)。varbinary消耗了row-size,
不同版本的mysql
mysql已经给orcale收购了,可能又闭源的风险。alisql是阿里提供的一种数据库。TiDB是一种类似MySQL的数据库。
MariaDB与MySQL
以下几点突出了MariaDB的优缺点。
优点
- MariaDB针对性能进行了优化,对于大型数据集,它比MySQL强大得多。从其他数据库系统可以优雅的迁移到MariaDB是另一个好处。
- 从MySQL切换到MariaDB相对容易,这对于系统管理员来说好像是一块蛋糕。
- MariaDB通过引入微秒级精度和扩展用户统计数据提供更好的监控。
- MariaDB增强了KILL命令,使您可以杀死用户的所有查询(KILL USER 用户名)或杀死查询ID(KILL QUERY ID query_id)。MariaDB也转而使用Perl兼容的正则表达 (PCRE),它提供比标准MySQL正则表达式支持更强大和更精确的查询。
- MariaDB为与磁盘访问,连接操作,子查询,派生表和视图,执行控制甚至解释语句相关的查询应用了许多查询优化。
- MariaDB纯粹是开源的,而不是MySQL使用的双重授权模式。一些仅适用于MySQL Enterprise客户的插件在MariaDB中具有等效的开源实现。
- 与MySQL相比,MariaDB支持更多的引擎(SphinxSE,Aria,FederatedX,TokuDB,Spider,ScaleDB等)。
- MariaDB提供了一个用于商业用途的集群数据库,它也支持多主复制。任何人都可以自由使用它,并且不需要依赖MySQL Enterprise系统。
缺点
- 从版本5.5.36开始,MariaDB无法迁移回MySQL。
- 对于MariaDB的新版本,相应的库(用于Debian)不会及时部署,由于依赖关系,这将导致必需升级到较新的版本。
- MariaDB的群集版本不是很稳定。
迁移到MariaDB的主要原因
- 首先,MariaDB提供了更多更好的存储引擎。NoSQL支持由Cassandra提供,允许您在单个数据库系统中运行SQL和NoSQL。MariaDB还支持TokuDB,它可以处理大型组织和企业用户的大数据。
- MySQL的平常(和缓慢的)数据库引擎MyISAM和InnoDB已分别在MariaDB中由Aria和XtraDB取代。Aria提供了更好的缓存,这对于磁盘密集型操作来说是有所不同的。
- MariaDB通过引入微秒级精度和扩展用户统计数据提供更好的监控。
- MariaDB的最新功能(如GIS,动态色谱柱支持等)使其成为更好的选择。
- MariaDB遵循良好的行业标准,同时发布安全公告和升级,并以正确的方式处理预发布的保密性和发布后的透明度。
join语法
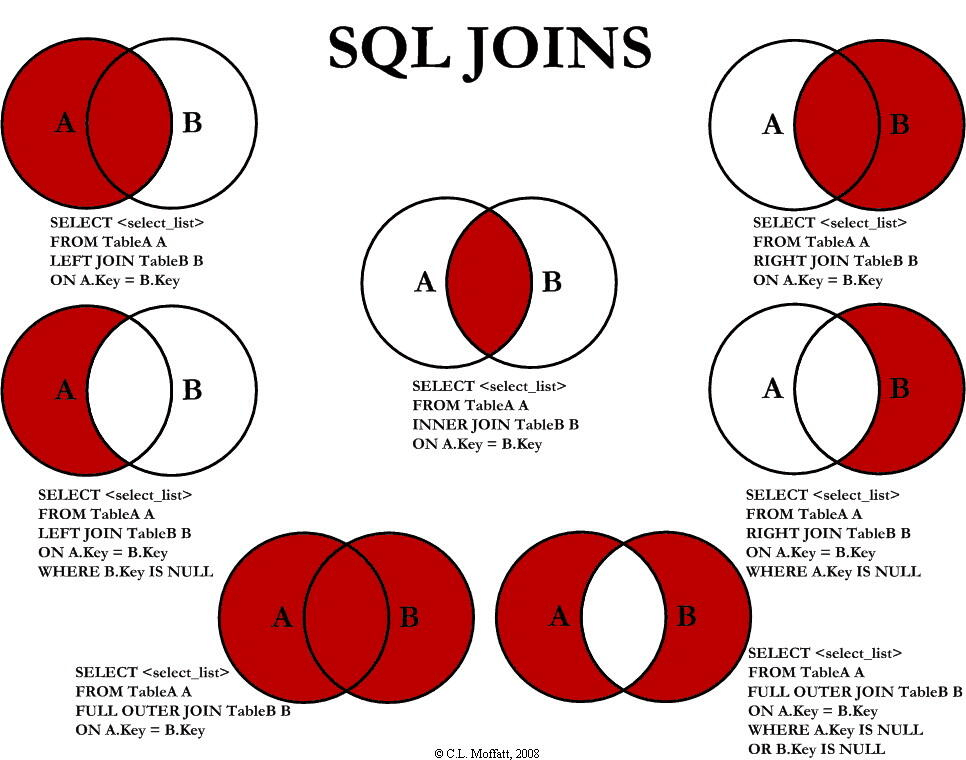
按照时间分组
主要是通过函数将时间戳转换成一个字符串,然后就能group by了。
1 | select from_unixtime(at2.payTime, '%Y-%m-%d'), sum(at2.amount) from alipay_trade at2 group by from_unixtime(at2.payTime, '%Y-%m-%d'); |
三表联表查询
这个实例里面有使用查询出来的子表,当成表去做LEFT JOIN。
1 | SELECT |
在update语句里面增加if语句
1 | Update ceremony_user |
1 | const [updatedCount] = await CeremonyUser.update({ |
简单的字符串操作
1 | select SUBSTR(nh.receiveAddress,3) as addr, nh.receiveAddress from nft_history nh where nh.receiveAddress like '%0x0x%'; |
时间函数
1 | /* 全局设置 */ |
修改时区的sql:
1 | SET GLOBAL time_zone = 'Asia/Shanghai'; |
1 | # 新建mysql的docker的时候指定时区 |
如果遇到实在不能修改时区,也可以在编辑器连接上去之后主动执行一个sql语句,将自己 mysql session 修改成 UTF+08:00
1 | SET time_zone = "+08:00"; |
自增字段造成的bug
这次遇到一个问题,有张表定义为自增的表,需要将由程序从其他地方读取,并且同步到这个数据表中,结果这个表的自增字段的当前值已经很大了,造成了插入数据老是会丢失。
可以使用mysql的工具来评估语句
explain select * from activity_limit limit 1;
使用node.js里面的sql orm来实现连表查询
1 | const count = await this.app.appModel.LockUser.count({ where: { isLock: true } }); |
INSERT INTO ON DEPLICATE KEY
1 | INSERT INTO table_name (column1, column2, column3, ...) |
处理csv的字符串
1 | Public Function BeforeSplit(szString As String) As String |
js解析方式:
拆分CSV一行数据可以使用JavaScript的String对象的split()方法,该方法可以将字符串按指定的分隔符拆分成数组。下面是一个使用JavaScript实现拆分CSV一行数据的代码:
1 | function parseCSVLine(line, delimiter = ',') { |
在上面的代码中,parseCSVLine(line, delimiter = ‘,’)函数接受两个参数。其中第一个参数line表示需要解析的CSV一行数据,第二个参数delimiter表示分隔符,默认为逗号。函数会将解析后的结果作为一个数组返回。
具体实现思路如下:
初始化哨兵变量start和end,用于记录每个字段的开始和结束位置。
初始化一个空数组result,用于保存解析后的字段值。
初始化一个布尔变量quoted,用于标记当前字符是否在引号内。
使用循环遍历字符串line的每个字符,并逐个检查是否到达字段的结束位置。
如果当前字符是指定的分隔符(且不在引号内),则提取出当前字段的值,并将下一个字段的开始位置设置为end + 1。
如果当前字符是引号,则将quoted设置为相反的值。
将end加1,继续进行下一轮遍历。
最后一个字段的结束位置就是字符串line的末尾,因此将最后一个字段提取出来并加入到result数组中。
完整的使用示例代码:
1 | const csvLine = '2,"福利商城",1,0,0,"[{""moneyType"": 0,""moneyParam"": 0},{""moneyType"": 6,""moneyParam"": 9},{""moneyType"": 6,""moneyParam"": 10}]"'; |
该代码会将CSV行数据中每个字段提取出来并输出到控制台中,输出结果应如下:
1 | [ '2', |
字段太长报错
1 | Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs |
大表创建索引
如果有一个表数据已经有60,000,000条数据了,现在我发现其中有两个字段作为条件查询的时,速度会非常慢,这个时候需要给这个表的两个字段创建索引,要如何做比较稳妥,增加索引是否会引发服务器顿卡?
在给一个拥有 60,000,000 条数据的表的字段创建索引时,可以采取以下步骤来确保操作的稳妥性并尽量避免服务器性能问题:
分析查询需求:首先,分析具体的查询需求,确定哪些字段是经常被用作查询条件的。这有助于决定应该为哪些字段创建索引。
评估索引对性能的影响:在给字段创建索引之前,需要评估索引对性能的影响。尽管索引可以提高查询速度,但它们也会增加数据插入、更新和删除的成本。使用 EXPLAIN 或其他数据库工具来查看查询计划,并评估索引是否会对性能产生显著的改善。
选择合适的索引类型:根据字段的特性和查询需求,选择合适的索引类型。常见的索引类型包括 B-树索引、哈希索引和全文索引。了解不同类型索引的适用场景,并选择最适合你的查询的索引类型。
逐步创建索引:考虑到表中的数据量较大,可以逐步创建索引,而不是一次性创建。可以先选择影响最明显的查询条件字段进行索引创建,然后观察性能的变化。在创建索引期间,可能会对服务器的性能产生一定的影响,但通过逐步创建可以减少冲击和控制风险。
设置维护时间窗口:为了减少索引创建对服务器性能的影响,可以在服务器的低峰期或维护时间窗口进行索引创建操作。这样可以降低对用户和应用程序的影响。
监测和优化:在索引创建完成后,进行性能监测,观察查询速度和服务器负载。如果发现任何性能问题,可以进一步优化查询语句、调整索引或考虑其他性能优化措施。
需要注意的是,索引的创建可能会对服务器的性能产生一定的影响,尤其是在大型表上。因此,在进行索引创建操作时,应事先评估和规划,并确保在适当的时间和方式下进行操作,以最大限度地减少潜在的性能问题。
upsert causes auto increment gap
https://stackoverflow.com/questions/3679611/mysql-upsert-and-auto-increment-causes-gaps
upsert 在 bigint 自增的情况下,将会出现问题。
delete 语句练习
1 | delete from t_news |
你的SQL语句看起来是在尝试删除一些特定的记录。不过,我注意到你的子查询可能存在问题,因为它试图在t_news表自身上使用group by和having,同时又在外部查询中使用了in。这可能会导致问题,特别是如果new_number在子查询和主查询中具有不同的含义。
让我们尝试重构这个查询,使用内联视图来提高可读性和效率:
1 | DELETE t1 |
在这个查询中,我们创建了一个内联视图(子查询)来找到重复的new_number。然后,我们将这个视图与原始的t_news表连接,删除满足条件(language为空)的记录。
dbeaver 在显示 timestamp 的时候,将时区显示出来
Selects, you can go to DBeaver Preferences:
->
yyyy-MM-dd HH:mm:ss Z z
yyyy-MM-dd HH:mm:ss
推荐一个在线设计表的工具
1 | Table users { |
也能支持直接将sql语句导入进来。
统计相关sql语句
1 | -- 这个例子用于统计注册用户,按照等级类型来统计数量 |
命令行中查看某个表的结构
1 | SHOW [EXTENDED] [FULL] {COLUMNS | FIELDS} |
按照组来查询
1 | SELECT * |
计算利润和提现之后是余额
1 | SELECT |
设置的数据包太小
1 | SQL 错误 [S1000]: Packet for query is too large (2,085 > 2,048). You can change this value on the server by setting the 'max_allowed_packet' variable. |
这个错误表明你在执行的 SQL 查询中使用的数据包大小超过了 MySQL 服务器允许的最大数据包大小。为了解决这个问题,你可以按照以下步骤调整 max_allowed_packet 变量的值:
登录 MySQL 服务器:
使用 MySQL 客户端或其他工具登录到 MySQL 服务器。
检查当前的 max_allowed_packet 值:
执行以下查询来查看当前的
max_allowed_packet值:1
SHOW VARIABLES LIKE 'max_allowed_packet';
设置新的 max_allowed_packet 值:
如果当前的
max_allowed_packet值较小,你可以通过以下方式设置一个更大的值:1
SET GLOBAL max_allowed_packet = 524288000; -- 例如,设置为 500 MB
请根据你的实际需求设置一个合适的值。这里设置的值是字节数,所以你可以根据需要调整。
重启 MySQL 服务器:
在一些情况下,修改
max_allowed_packet后,需要重启 MySQL 服务器才能使更改生效。1
sudo service mysql restart
请注意,修改 max_allowed_packet 可能会影响系统性能和网络带宽使用,因此需要谨慎调整这个值。确保将其设置为满足你应用需求的合理值。
ALTER USER ‘root‘@’localhost’ IDENTIFIED BY ‘新密码’;
FLUSH PRIVILEGES;
以下是格式化后的 SQL 语句,通过适当添加缩进和换行,使其结构更加清晰易读:
1 | SELECT |
上述 SQL 语句的大致逻辑如下:
- 首先在子查询中(最内层括号部分),针对
tb_callback表按照order_id进行分组,通过MAX(id)找出每个order_id分组下id的最大值,并将其命名为max_value。 - 接着,在中间层的子查询(从
JOIN ( SELECT t1.*...开始到内层JOIN结束这部分),将tb_callback表(t1)和上一步得到的结果(t2)进行连接,筛选出tb_callback表中每个order_id分组下id为最大值对应的那些记录(也就是每个order_id对应的最新记录,假设id是有顺序意义的递增字段)。 - 然后,将
tb_my_order表(t4)和上述子查询得到的结果(t3)基于t4.inner_order_id = t3.order_id这个条件进行连接。 - 最后,通过
WHERE条件t4.residue <> t3.residue筛选出两表连接后,residue字段值不相等的记录,并返回指定的id、inner_order_id、residue以及别名real_residue等字段信息。
希望这样的格式化和解释对你理解该 SQL 语句有所帮助。
mysql
Public Key Retrieval is not allowed
这个错误:
Public Key Retrieval is not allowed
通常出现在使用 MySQL 8.x + JDBC 连接字符串 时,尤其是密码使用了 caching_sha2_password 认证插件,客户端无法获取服务器的公钥来加密密码。
allowPublicKeyRetrieval 设置为 true
⸻
🧠 背景说明
从 MySQL 8.0 开始,默认的用户认证插件改成了:
caching_sha2_password
而旧版 JDBC 驱动(或配置不当的)在使用用户名密码连接时,需要获取服务器的公钥进行加密,但默认禁用了该功能。
⸻
✅ 解决方法
✅ 1. 修改 JDBC URL,加上 allowPublicKeyRetrieval=true
这是最直接的办法:
jdbc:mysql://localhost:3306/yourdb?allowPublicKeyRetrieval=true&useSSL=false
你也可以加上编码参数以完整示例:
jdbc:mysql://localhost:3306/yourdb?useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=UTC&characterEncoding=utf8
⸻
✅ 2. 或者:把 MySQL 用户改成 mysql_native_password(兼容旧驱动)
如果你不想改连接串,也可以把用户的认证方式换回以前的:
ALTER USER ‘youruser‘@’%’ IDENTIFIED WITH mysql_native_password BY ‘yourpassword’;
FLUSH PRIVILEGES;
然后再试试连接。
⸻
⚠️ 注意事项
• allowPublicKeyRetrieval=true 只在 SSL 为 false 时有效;
• 如果你用了 SSL,就不要设置它,而应该使用 serverRSAPublicKeyFile 参数传入公钥文件路径。
⸻
如果你愿意提供你的完整连接串或使用框架(比如 Spring Boot、GORM 等),我可以帮你改成正确的格式。你现在是在哪儿用这个连接?Golang?Java?Python?
参考
- [1] stackoverflow-varbinary-vs-blob-in-mysql
- [2] MySQL5.0-blob手册
- [3] MySQL5.7-varbinary手册
- [4] 无邪-为什么MariaDB更优于MySQL
- [5] 知乎-TiDB介绍
- [6] PingCAP-TiDB
- [7] MariaDB-varbinary
- [8] MySQL大字段问题