概述
在Redis5.0(GA October 2018)之后提供的了流这个数据结构,它以更加抽象的方式对日志数据结构重新建模。尽管日志本质上依然完备:类似日志文件一样,经常实现类似以append-only模式打开的的文件。Redis Streams首先是一个只能追加的数据结构。由于是一种内存抽象数据类型,至少在理论上,因此实现了强大处理能力能克服日志文件的限制。
Streams
开始
是什么让Redis streams成为Redis里面最复杂的类型,抛开它自身非常简单的数据结构,事实上是它实现了附加的,非强制的特性:一个阻塞操作允许消费者等待新数据被生产者增加到stream里面,此附加的概念叫做Consumer Groups。
消费组最初被引入是被流行的消息系统Kafka提出的。Redis通过完全不同的角度重新实现了类似的想法,但是目标是一致的:允许一组不同的clients去消费相同的stream消息。然而,注意,List也有一个可选的更复杂的阻塞API,通过类似BLPOP命令。所以Streams在规则上和Lists没有太多区别,它只是增加了附加API变得更加复杂和强大。
流基础
为了了解Redis Streams是什么,如何使用它们,我们将忽略一些高级特性,将聚焦它本身的数据结构,从命令行的角度介绍访问维护它的惯用方法。基本上这些方法,在大多数Redis数据结构共有的部分,比如list,Sets,Sorted Set等。
因为Streams是只能附加的数据结构,使用XADD写命令,附加项到指定的stream。项不仅仅只是string,也能填充一个或者多个域-值模式数据。这样,里的每个条目都已经结构化,例如以CSV格式编写的附加文件,其中每行中存在多个单独的段。
1 | > XADD mystream * sensor-id 1234 temperatur 19.8 |
上面的命令将会附加sensor-id: 1234,temperatur: 19.8条目到以mystream为key的流里面,从命令行里面返回了一个用于标识自动生成的项,1518951480106-0。它第一个参数是key的名称,第二个参数是指定entry ID用于区别于在streams内部的编号。然而,在这个实例中,我们使用了*,因为想生成一个新的ID。每个新的ID都将单调增加,所以跟简单的来说,每个新的项加入将会使用比已经加入的项都大的ID号。大多数时候自动生成ID都是你需要使用的,指定ID方式操作是非常罕见。我们将会在稍后更多讨论此话题。事实上每个Stream条目都有各自的ID,类似log文件中的行号,偏移字节数,能用于标识项。反过头来看我们的XADD例子,在key和ID之后,后面就是我们想存入Stream条目的域-值对。
我们可以使用XLEN获取当前Stream的长度。
1 | > XLEN mystream |
条目编号
Entry IDs
XADD命令返回的项ID,明确标识了每个stream里面的条目,它包含两个部分组成
1 | <millisecdsTime>-<sequenceNumber> |
前面是产生entry的本地Redis节点时间戳(精确到毫秒),然而如果当前当前时间戳小于前面的entry节点,将使用前面的节点时间戳替换此值,所以如果本地时间戳滞后了也一样能维持单调增长。sn用于同一毫秒创建时做分辨,由于这个数值是64bit,可以近似当成无限制标识entries。
这种格式的IDs第一眼就看起来很奇怪,gentle的读者将会奇怪为什么时间会当成ID的一部分。原因是Redis streams支持对ID范围做查询。因为ID关系到条目的生成时间,提供了一种方便的按照时间来查询方式。我们将在接下来看到转化过的XRANGE方式。
如果有某种原因我们需要自增IDs不与时间相关,取而代之使用外部系统ID,如前所述,XADD命令能使用显示ID,而不是通配符*来禁止触发自动生成机制。示例如下:
1 | > XADD somestream 0-1 field value |
注意在这个情况下,最小的ID是0-1了,命令行将不会支持小于它的任何值了。
1 | > XADD somestream 0-1 foo bar |
这里也可以使用明显的ID替换掉milliseconds部分,而让sequence部分维持自增。
1 | > XADD somestream 0-* baz qux |
从流中获取数据
Getting data from Streams
现在我们最终能通过XADD添加条目到我们的stream。当追加数据到到stream非常明显了,然而,从stream里面提取出来数据就不是那么明显了。如果我们继续类比日志文件,一个明显的方式模仿UNIX的命令tail -f,我们可以开始监听以便于获取什么新的消息被加入到了流中。注意不类似于Redis阻塞列表操作,这里提供了元素给单个客户端,以阻塞方式弹出风格类似于BLPOP,使用流时我们想有众多消费者都能看到新消息被添加到流中(相同的方式多个tail -f进程都能看到什么内容被加入到log中)。使用传统术语我们想流能扇出多个消息给多个客户端。
但是,这只是潜在的一种访问模式。我们可能也需要使用完全不同的方式查看一个流:不同于消息系统,而是按照时间序存储系统。在这种情况下可能它可能是非常有效的—去获取最新的数据被添加,通过时间跨度或者使用迭代器使用游标去依次遍历全部历史数据也是一种很常见的查询模式。很明显后者是非常有用的一种访问模式。
最后,我们从消费者的视角来看,我们可能想要访问一个流通过另一种模式,那就是,流里面的一个条目能被分配给多个消费者去处理这些数据,以便消费组只能看到单个流到达的消息子集。这种方案,能将消息分配给不同的消费者来处理,而不是单个消费者处理全部的消息:每个消费者将会获取不同的消息来处理。这个基本上就是Kafka在消费组里面做的工作。通过消费组从一个流中获取数据是另外一种模式。
Redis流通过不同的命令支持以上三种查询模式。下章节将会演示这些方式,先从最简单、最直接的方介绍:范围来查询。
通过范围条件查询
Querying by range: XRANGE and XREVRANGE
通过指定两个IDs来查询某个范围内的数据。将会返回[start,end]之间的元素,使用符号-和+标示最小和最大的ID。
1 | > XRANGE mystream - + |
每个条目返回值包含两个项目:ID和域-值对的列表。我们已经说过条目IDs和时间存在相关性,因为-左边部分就是这个节点被创建出来当时的Unix时间戳(单位为毫秒)。这也就意味着我们可以通过时间为单位去查询范围内的数据。为了这么做,然而,我们需要忽略掉id中sequence部分:如果忽略,意味着将会读取sequence从0到最大值之间的数据。通过这种方式,我们就能查询两个Unix时间戳之间的数据。下面是通过两个时间戳查询信息:
1 | > XRANGE mystream 1518951480106 1518951480107 |
我只有单条数据在这个范围,但是在真实数据集中,我可能查询跨度以小时为单位的数据,或者可能在两毫秒内有两条记录,也有可能返回信息非常的巨大。出于这个原因,XRAGE支持使用COUNT的选项。这样我们就能截取N个项。
1 | > XRANGE mystream - + COUNT 2 |
如果我们想继续查询后续的元素可以使用(前缀
1 | > XRANGE mystream (1519073279157-0 + COUNT 2 |
XRANGE的复杂度,查询O(log(N)),返回M个元素O(M),这是较小的log时间复杂度,意味着每次迭代将会非常的快速。所以XRANGE事实上就是流的迭代器,不需要去使用XSCAN命令。
XREVRANGE相当于XRANG但是返回数据是反序的,下面这个练习就是从流中读取最后一个项。
1 | > XREVRANGE mystream + - COUNT 1 |
注意这条XREVRANGE命令命令将获取从start到stop参数反序的内容。
使用XREAD监听新消息到达
Listening for new items with XREAD
当我们不想去通过范围去访问在流中批量的项时,通常我们订阅新消息到达了流。这个概念可能在Redis消息订阅发布里面出现过,你可以订阅一个频道或者是阻塞式的列表,当你等待一个key下获取新元素,但是这里消费流行为存在几点区别:
- 一个流能被多个消费者等待数据,每个新项,默认情况下将会派分给全部的在等待消息的消费者。这种方式不同于阻塞列表,阻塞列表每个消费者会获取不同的元素。然而,扇出给多消费者技术类似于Pub/Sub。
- 当Pub/Sub消息被fire或者forget将永远不会被存储,使用阻塞队列,当一个消息被客户端从list中poped,流的处理也是有本质的差异。全部消息都无限制的追加在流末尾(除非用户明显要求去删除项):不同的消费者将会知道什么是新消息从他自己记录的最后消费的ID。
- 流消费组提供了一个水平控制是Pub/Sub或者阻塞列表无法实现的,为相同的流配置不同的组,明确确认已处理项,可以查看被挂起的项,什么未处理项,每个客户端连续历史记录可见性,都只能看到私人的过去历史记录。
XREAD提供了监听新消息到达功能。它将会比XRANGE更加复杂,所以我们开始用最简单的方式,之后再将这个展开。
1 | > XREAD COUNT 2 STREAMS mystream 0 |
上面是非阻塞方式的XREAD。注意COUNT选项不是强制的,在事实上只有STREAMS选项,这里制定了一系列key以及大于命令输入的ID号更大的消息。
在上面命令中我们写道STREAMS mystream 0表示我们要获取从mystream全部的数据,条件为ID大于0-0。我们可以看到命令将会返回key name,因为这个命令能支持输入多个key。我们也能写这样的语句STREAMS mystream otherstream 0 0。这个选项都是最后一项。
不同于XREAD能一次性访问多个stream,我们能指定last ID我们拥有获取最新消息,在简单模式指令不会和XRANGE作比较。但是,有趣的地方是我们能通过XREAD指定BLOCK参数,轻松进入阻塞模式。
1 | XREAD BLOCK 0 STREAMS mystream $ |
BLOCK选项设置了一个0毫秒的超时时间(意味着永不超时)。另外,我们制定了$来替换0这个ID号。这就意味着刚刚存进来的最大的项的编号。所以我们只会在新消息到达的时候,才会处理。这个有些类似tail -f。
XREAD只需要指定多个key就能监听多个流。如果请求同步服务,因为至少一个流的元素大于我们设定的ID,它将会返回结果。否则,这个命令将会阻塞直到返回第一个最新到达的数据(遵循指定的ID)。
类似于阻塞列表操作,阻塞流读是一种公平的客户端等待数据的模式,语义上最寻先进先出模式。第一个客户端阻塞在流上将会第一个由于数据到达被解锁。
XREAD除了COUNT/BLOCK没有其他的选项,它是一个基础的命令指定试图去消费一个或者多个的流。更多功能需要使用消费组API,然而通过消费组读取是使用到XREADGROUP,下章节将会涉及到。
消费组
Consumer groups
不同客户端处理相同流,当手头的任务时使用来自于相同流,这样XREADY已经提供了一种方式扇出给多个客户端,可能用了副本以提供更多的读取扩展性。尽管确定的问题时我们不想要提供同一个流消息给太多客户端,而是提供不同的流中消息子集给多个客户端。在明显的案例里—这是有用的方式—一些消息处理起来比较慢速:拥有多个工作线程接受流中不同的部分消息能让我们扩展消息处理,通过分流不同消息给不同的准备干活的客户端。
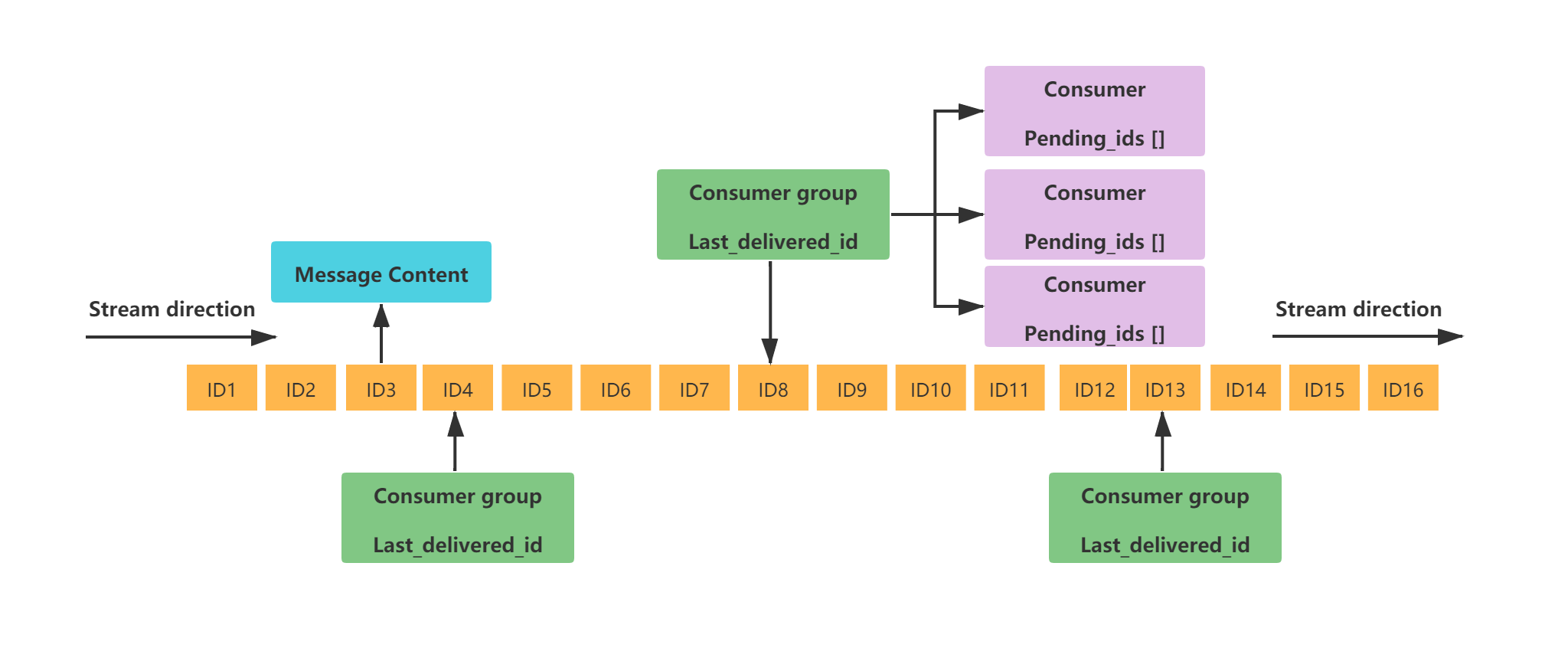
实际场景中,如果我们想象有3个消费者C1, C2, C3,一个流包含了1, 2, 3, 4, 5, 6, 7消息,那么我们想根据下面图表来处理消息:
1 | 1 -> C1 |
为了达成这个,Redis使用一个叫做消费组的概念。Redis消费组和Kafka消费组无关。虽然它们在功能上相似。
消费组像一个从流中取数据的伪消费者,事实上被多个消费者服务,提供确定性保证:
- 每个消息被服务给不同的消费者以便不可能将相同消息投递给多个消费者。
- 在消费组里面消费者都被使用名字标识,名字是大小写敏感的字符串,而且在实现消费者时避暑指定。意味着甚至经历短线,消费组还会保留全部状态,因为客户端将会重新声称自己属于相同的消费者。意味着客户端需要提供唯一的标识。
- 每一个消费组都有第一从未被消费ID的概念,因此,当消费者请求一个新消息时,他提供一条消息内容说还没有传递消息。
- 消费消息,要求使用指定的命令明确的反馈。Redis解释这个反馈为:这个消息被正确的处理它能被从消费组里面驱除出去。
- 消费组查询当前被挂起的全部消息,这些消息是我们派分给相同消费组中的其他消费者,但是还没有返回ack。感谢此特性,当访问流历史消息,每个消费者只能看到自己被派分了那些消息。
这种方式,消费组能被想象成流的一种状态。
1 | +----------------------------------------+ |
如果从这个视角来看,非常容易理解消费组能做到的事情,它如何通过提供消费者以及消费者们挂起的消息,以及消费者如何请求新消息将会被返回消息号大于last_delivered_id。在相同时候,如果你查询消费组当它是Redis流辅助数据结构,它将会非常明显—单个流能提供给多个不同集合消费者的消费组。实际上,它甚至有可能是相同流有客户端不通过消费组而是通过XREAD来读取,或者在不同消费组里客户端通过XREADGROUP读取消息。
现在是时候聚焦看啊可能消费组的基础。
- XGROUP 用于创建、销毁和管理消费组。
- XREADGROUP 用于读取流上消费组。
- XACK 允许消费者标记一个挂起的消息成为正常处理的消息。
创建消费组
Creating a consumer group
假设我已经有个mystream的流,我们可以通过下面的命令创建一个消费组。
1 | > XGROUP CREATE mystream mygroup $ |
如你所见上面的命令当创建一个消费组需要指定一个ID,在例子里面是美元符号。在组被创建是需要指定最后的消息编号,以便于消费组中第一次链接上来的消费者知道下一个处理的消息是什么。如果我们设置表示从现在开始,最新的消息到达了之后我们才会处理。如果设置0将会从流中历史上开始的位置开始处理。当然你可以指定任意一个有效的ID。消费组将会投递ID号比我们指定的消息给我们。
XGROUP CREATE也支持自动创建流,如果它不存在,使用MKSTREAM子指令附加在最后面。
1 | > XGROUP CREATE newstream mygroup $ MKSTREAM |
现在消费组被创建我们可以立刻尝试使用XREADGROUP指令读取数据。我们将从两个消费者—Alice Bob读取,看系统将返回给他们两个不同数据。
XREADGROUP和XREAD相似提供了类似BLOCK选项,另外他是同步命令。GROUP选项是强制需要的,它有两个参数:消费组名称,读取消息的消费者名字。选项COUNT也支持,和XREAD相同。
先我们输入一些数据到流中
1 | > XADD mystream * message apple |
- 注意:这里消息的域名,和关联的数值为蔬果名称,建议使用流项都是用相同的词汇。
这里我们将使用消费组试图读取流数据:
1 | > XREADGROUP GROUP mygroup Alice COUNT 1 STREAMS mystream > |
XREADGROUP和XREAD返回数据相同。命令里面提供了组编号,消费者名称。表示了Alice去读取了mygroup。每次一个消费者通过消费组执行了操作,需要指定唯一标识的消费者名称。
上面命令中有一个非常重要的细节,在STREAMS选项mystream后面制定了一个>。这个ID只有在消费组前提下有效,它的意义是:消息永远不要投递给其他的消费者。
恢复失效的条目
Recovering from permanent failures
上面的里面让我们编写消费组包含多个消费者,每个消费者分别处理不同集合的消息,当它们从灾难恢复过来之后将重新读取派分给它的挂起消息。尽管现实世界里消费者可能永远失败且无法恢复。某些原因消费者再也无法恢复,被此消费者挂起的消息将会发生什么?
Redis消费组提供了用于声明被某个消费者挂起消息切换所有权的功能,将会重新派分给不同的消费者。这个功能非常明显。消费者去访问挂起列表,使用特定的命令声明指定的消息,否则服务器将会让这个消息永远挂起在老消费者上。用此方法不同应用可以选择是否使用此功能,明显的了解如何使用它。
第一步使用XPENDING指令显示消费组中挂起的条目。这个是只读命令,它通常安全读取并且不会修改任何消息的所属权。这个命令最简单的格式是只有两个参数:流名称,消费组名称。
1 | > XPENDING mystream mygroup |
通过这个方法,将挂起在流中消息总数(当前是两条),最后是挂起消息的消费者以及TA挂起的消息数目。我们现在只有Bob挂起了两个消息,因为一条消息Alice请求的已经通过XACK确认过了。
我们可以更多参数从XPENDING中获取更多信息,下面是指令全部形态
1 | XPENDING <key> <groupname> [[IDLE <min-idle-time>] <start-id> <end-id> <count> [<consumer-name>]] |
通过提供开始结束ID(可以类似于XRANGE的-/+),count可以控制输出的条目数量,我们可知道更多关于挂起消息的信息。选项末尾,消费者是可选项,如果我们只想知道挂起消息数量可以通过这种指令得到。
1 | > XPENDING mystream mygroup - + 10 |
现在我们可以获得下里面的详细信息:ID,消费者名称,空闲时间(单位ms),过去了多少毫秒最后一个消息被投递给某个消费者,最后给定的消息被投递了多少次。我们有两个消息给了Bob,消息被空闲了74170458毫秒,差不多20小时。
注意:没有人组织我们去通过使用XRANGE检查第一个消息的内容。
1 | > XRANGE mystream 1526569498055-0 1526569498055-0 |
我们输入了两次相同的ID参数。现在我们有新的想法,Alice可能决定20小时没有处理消息,Bob这段时间可能没有恢复,这个时候去声明这条消息被唤醒替换Bob处理给Alice处理。为了做这个,我们可以通过XCLAIM命令。
这个命令全选项模式非常复杂且有效,当他被用于响应消费组修改,但是我们将会使用我们通常使用的参数来做到这一点。在这个情况下它是这样的:
1 | XCLAIM <key> <group> <consumer> <min-idle-time> <ID-1> <ID-2> ... <ID-N> |
我们制定了key和组,我想要让指定的ID的消息修改所有权,而且将会被赋值给指定的消费者名称。然而,我们也提供最小停留时间,如此操作将会在停留时间超过我们设定的时间的消息上生效。这个将会非常有用,因为可能两个客户端试图都去声明一个消息在同一个时刻:
1 | Client 1: XCLAIM mystream mygroup Alice 3600000 1526569498055-0 |
然而,边界效应下,声明消息将会重置空闲时间而且增加分发计数,所以第二个客户端将会声明它失败。通过这种方式我们轻松杜绝了重复处理消息的情况。
这个是命令执行的结果:
1 | > XCLAIM mystream mygroup Alice 3600000 1526569498055-0 |
消息已经重新被Alice声明了,她现在可以处理这个消息并且确认此消息,她能让事情往前推进不管原始的消费者还未恢复。
自动化索取
Automatic claiming
Redis 6.2版本(GA October, 2021)中添加XAUTOCLAIM命令,实现了我们已经在上面讨论过的处理。XPENDING和XCLAM为不同的恢复机制提供基础构建的方式。这个命令为大多数恢复需求提供了通用、优化、简单的解决方案。
XLAUTOCLAIM定制了空闲挂起消息和将其关系转换给其他消费者。这个命令长这样
1 | XAUTOCLAIM <key> <group> <consumer> <min-idle-time> <start> [COUNT count] [JUSTID] |
在上面的例子中,我们可以自动索取一个消息通过这种方式:
1 | > XAUTOCLAIM mystream mygroup Alice 3600000 0-0 COUNT 1 |
类似XCLAIM,指令将会返回索取的消息列表,而且他返回了流的ID,以便于使用迭代方式访问全部挂起的条目。流ID是一个游标,我们可以使用它下次调用的时候抓取接下来的挂起消息:
1 | > XAUTOCLAIM mystream mygroup Lora 3600000 1526569498055-0 COUNT 1 |
当XAUTOCLAIM返回”0-0”流ID当成一个游标,这就意味着到达挂起条目的尾部。这不意味着没有新的挂起的消息,所以矗立着可以继续通过调用XUTOCLAIM从流的头部重新开始抓取。
索取和派分计数
Claiming and the delivery counter
计数器查看通过XPENDING可以输出每个消息的派分次数。计数将会通过两种方式增加:1.当消息被成功的通过XCLAIM索取2.通过XREADGROUP途径访问历史挂起消息。
当发生了错误,通常消息将会被多次派分,但是事实上它会被处理和确认。然而可能有个问题出现在特定的消息,因为消息的错误造成每次代码执行都是出问题。这种情况造成消费者持续的错误的处理这条消息。因为我们有实现了投递次数的机制,我们可以使用计数检测出某些消息无法被正常的处理。所以一旦投递计数大于你指定的一个计数上限,明治之举是将这个消息放入其他的流中,并且发起通知给系统管理员。通过基本的方法Redis流实现了死亡信的概念。
流的可观察性
Streams observability
消息系统缺乏可视化方法将很难使用。不清楚谁正在消费消息,什么消息被挂起,有什么消费组工作在指定的流,将会让事情不明朗。因此Redis流和消费组有不同方式去观察正在发生声明。我们已经学习了XPENDING,这个指令让我们可以看到此刻在处理的消息列表,包括这个消息的空闲时间、投递次数。
我们想做更多,XINFO命令以及子命令提供了获取流和消费组的更多信息。
命令使用子命令一遍提供关于流和消费组不同的信息。比如XINFO STREAM输出流的报告信息:
1 | > XINFO STREAM mystream |
输出信息显示了关于流的内部编码,也显示了第一条、最后一条信息。另外一块数据是关联在流上的消费组有效个数。我们可以通过下面指令提取更多关于消费者组的信息
1 | > XINFO GROUPS mystream |
如你所见,XINFO命令输出了域-值项。以为这种输出是人立即能理解的信息,而且允许命令去报告更多信息在将来版本中添加的功能不会打破和老版本程序的兼容性。另外一个命令时一种广泛应用的指令,如XPENDING,只会输出这些除field名称之外的信息。
上述例子使用了GROUPS子目录输出,能被清晰的呈现field名称。我们可以检查指定消费组详细状态通过检查消费者注册在组里面。
1 | > XINFO CONSUMERS mystream mygroup |
可以通过查阅手册获取想要知道的指令详情:
1 | > XINFO HELP |
与Kafka的差异
Differences with Kafka(TM) partitions
Redis流中消费组和Kafka有类似的点,但是Redis在是线上有非常多的不一致。分片只是逻辑上的而且消息只会放入单个Redis键,这种方式不同的正在等待新消息的客户端可以基于这个来提供服务,而不是从分片客户端读取。举个例子,如果消费者C3在相同位置永久的失败,Redis将会在新消息到达时继续让C1,C2继续处理,如同现在只有两个逻辑分片。
类似的,如果有一个消费者处理速度比其他的消费者都快,这个消费者将会在单位时间内将收到更多的消息。Redis可以很明确查询到全部没有被处理的消息,而且记录谁第一次收到某条消息且从未被人处理过。
这也就意味着在Redis如果你真的想去为多个Redis实例中相同的流去制作分片消息,你可以使用多重键和共享系统如Redis集群或者一些其他的应用级的共享系统。单个Redis流不会自动分片给多实例。
我们可以说有下列结论:
- 如果你使用1个流->1个消费者,你将顺序处理数据。
- 如果你使用N流->N消费者,每个给定的消费者将会命中N个流中的一些子集,你可以扩展1流->1消费者模型。
- 如果你使用1流->N消费者,可以实现负载均衡给N个消费者,在这个方案中,消息在这里面处理将会打乱次序,因为可能给定的消息可能被一个处理更快的消费者先处理完成。
基本上Kafka分片更像N个不同的Redis键,而Redis消费组是服务端负载均衡系统提供给1个流N个消费者。
流的上限
Capped Streams
许多应用不想去永久将信息放入流中。有时候我们需要为流设置一个最大值,某个时候数值达到了我们设置的值,将Redis的一些数据从内存中移动到存储器中,提供历史备份。Redis流已经为此提供了支持。XADD的一个选项MAXLEN。这个非常容易使用。
1 | > XADD mystream MAXLEN 2 * value 1 |
使用MAXLEN当达到指定的长度时,旧的条目会被自动驱逐,因此流的大小保持不变。目前没有选项可以告诉流只保留不超过给定时间段的项目,因为这样的命令为了始终如一地运行,可能会阻塞很长时间以驱逐项目。例如,想象一下如果有一个插入尖峰,然后是长时间的停顿,然后是另一个插入,所有这些都具有相同的最大时间会发生什么。流将阻塞以驱逐在暂停期间变得太旧的数据。因此,用户需要做一些计划并了解所需的最大流长度是多少。此外,虽然流的长度与所使用的内存成正比,但按时间修剪不太容易控制和预测:
然而,使用MAXLEN进行修剪可能会很昂贵:流由宏节点表示为基数树,以便非常节省内存。改变由几十个元素组成的单个宏节点并不是最优的。因此可以使用以下特殊形式的命令:
1 | XADD mystream MAXLEN ~ 1000 * ... entry fields here ... |
MAXLEN~选项和实际计数之间的争论意味着,我真的不需要这正好是 1000 个项目。它可以是 1000 或 1010 或 1030,只要确保至少保存 1000 个项目即可。使用此参数,仅当我们可以删除整个节点时才执行修剪。这使它更有效率,而且它通常是你想要的。
还有一个命令,它执行的操作与上面的MAXLENXTRIM选项非常相似,除了它可以自行运行:
1 | > XTRIM mystream MAXLEN 10 |
或者,至于XADD选项:
1 | > XTRIM mystream MAXLEN ~ 10 |
但是,XTRIM旨在接受不同的修剪策略。另一种修剪策略是MINID,它驱逐 ID 低于指定 ID 的条目。
作为XTRIM一个显式命令,用户应该知道不同修剪策略可能存在的缺点。
未来可能添加的另一个有用的驱逐策略XTRIM是通过一系列 ID 删除以方便使用,XRANGE并XTRIM在需要时将数据从 Redis 移动到其他存储系统。
流API中的特殊ID
您可能已经注意到,在 Redis API 中可以使用几个特殊的 ID。这是一个简短的回顾,以便它们在未来更有意义。
前两个特殊 ID 是-和+,并且在使用XRANGE命令的范围查询中使用。这两个 ID 分别表示可能的最小 ID(基本上是0-1)和可能的最大 ID(即18446744073709551615-18446744073709551615)。正如你所看到的,它写起来更干净,-而+不是那些数字。
然后是我们想说的API,流中ID最大的项目的ID。这是什么$意思。因此,例如,如果我只想要新的条目,XREADGROUP我使用这个 ID 来表示我已经拥有所有现有的条目,而不是将来插入的新条目。同样,当我创建或设置消费者组的 ID 时,我可以将最后交付的项目设置为$,以便将新条目交付给组中的消费者。
正如您所看到$的,这并不意味着+它们是两个不同的东西,+每个可能的流中可能$的最大 ID 是,而包含给定条目的给定流中的最大 ID 是。此外,API 通常只能理解+or $,但避免加载具有多种含义的给定符号很有用。
另一个特殊的 ID 是>,这是一个特殊的含义,仅与消费者群体相关,并且仅在使用XREADGROUP命令时。这个特殊的 ID 意味着我们只需要迄今为止从未交付给其他消费者的条目。所以基本上>ID 是消费者组的最后交付的 ID。
最后*,只能与XADD命令一起使用的特殊 ID 意味着为我们自动选择新条目的 ID。
所以我们有-, +, $, >and *, 并且都有不同的含义,而且大多数时候,可以在不同的上下文中使用。
持久性、复制和消息安全
与任何其他 Redis 数据结构一样,Stream 被异步复制到副本并持久化到 AOF 和 RDB 文件中。然而,可能不那么明显的是,消费者组的完整状态也被传播到 AOF、RDB 和副本,因此如果消息在主服务器中挂起,副本也将具有相同的信息。同样,重启后,AOF 将恢复消费者组的状态。
但是请注意,Redis 流和使用者组是使用 Redis 默认复制进行持久化和复制的,因此:
- 如果消息的持久性在您的应用程序中很重要,则必须将 AOF 与强大的 fsync 策略一起使用。
- 默认情况下,异步复制不保证复制XADD命令或消费者组状态更改:在故障转移之后,可能会丢失某些内容,具体取决于副本从主服务器接收数据的能力。
- 该WAIT命令可用于强制将更改传播到一组副本。但是请注意,虽然这使得数据丢失的可能性很小,但由 Sentinel 或 Redis Cluster 操作的 Redis 故障转移过程仅会尽最大努力检查故障转移到最新更新的副本,并且在某些特定故障条件下可能会促进缺少一些数据的副本。
因此,在使用 Redis 流和消费者组设计应用程序时,请确保了解应用程序在故障期间应具有的语义属性,并相应地进行配置,评估它对于您的用例是否足够安全。
从流中删除单个项目
流还有一个特殊的命令,用于从流的中间删除项目,仅通过 ID。通常对于仅附加的数据结构,这可能看起来像一个奇怪的功能,但它实际上对于涉及隐私法规的应用程序很有用。调用该命令XDEL并接收流的名称,后跟要删除的 ID:
1 | > XRANGE mystream - + COUNT 2 |
然而,在当前的实现中,直到宏节点完全为空时,内存才真正被回收,所以你不应该滥用这个特性。
零长度流
流和其他 Redis 数据结构的区别在于,当其他数据结构不再有任何元素时,作为调用删除元素的命令的副作用,键本身将被删除。例如,当调用ZREM将删除排序集中的最后一个元素时,排序集将被完全删除。另一方面,流被允许保持为零元素,这既是因为使用了计数为零的MAXLEN选项(XADD和XTRIM命令),也因为XDEL被调用了。
之所以存在这种不对称,是因为 Streams 可能有关联的消费者组,我们不想因为流中不再有任何项目而丢失消费者组定义的状态。目前,即使没有关联的消费者组,流也不会被删除。
消费消息的总延迟
XRANGE像和XREAD不带 BLOCK 选项的非阻塞流命令像XREADGROUP任何其他 Redis 命令一样同步服务,因此讨论此类命令的延迟是没有意义的:在 Redis 文档中检查命令的时间复杂度更有趣。应该说流命令在提取范围时至少与排序集命令一样快,而且XADD速度非常快,如果使用流水线,可以在普通机器中轻松地每秒插入 50 万到 100 万个项目。
但是,如果我们想了解处理消息的延迟,那么延迟就变成了一个有趣的参数,在消费者组中阻塞消费者的上下文中,从通过 产生消息XADD的那一刻到消费者因为XREADGROUP返回而获得消息的那一刻与消息。
服务受阻消费者的工作原理
在提供执行测试的结果之前,了解 Redis 使用什么模型来路由流消息(以及实际上如何管理等待数据的任何阻塞操作)是很有趣的。
- 被阻塞的客户端在哈希表中被引用,该哈希表将至少有一个阻塞消费者的键映射到等待该键的消费者列表。这样,给定一个接收数据的密钥,我们可以解析所有正在等待此类数据的客户端。
- 当发生写入时,在这种情况下,当XADD调用命令时,它会调用signalKeyAsReady()函数。此函数会将密钥放入需要处理的密钥列表中,因为这样的密钥可能有针对被屏蔽消费者的新数据。请注意,此类就绪键将在稍后处理,因此在同一事件循环周期的过程中,该键可能会收到其他写入。
- 最后,在返回事件循环之前,最后处理就绪键。对于每个键,扫描等待数据的客户端列表,如果适用,这些客户端将接收到达的新数据。在流的情况下,数据是消费者请求的适用范围内的消息。
如您所见,基本上,在返回事件循环之前,客户端调用XADD和被阻塞以消费消息的客户端都会在输出缓冲区中获得回复,因此调用者XADD应该大约在同一时间收到来自 Redis 的回复消费者将收到新消息。
该模型是基于推送的,因为将数据添加到消费者缓冲区将直接通过调用操作执行XADD,因此延迟往往是可以预测的。
延迟测试结果
为了检查这些延迟特性,使用多个 Ruby 程序实例执行测试,这些实例推送消息,该消息具有作为附加字段的计算机毫秒时间,以及 Ruby 程序从消费者组读取消息并处理它们。消息处理步骤包括将当前计算机时间与消息时间戳进行比较,以了解总延迟。
获得的结果:
1 | Processed between 0 and 1 ms -> 74.11% |
因此,99.9% 的请求延迟 <= 2 毫秒,异常值仍然非常接近平均值。
向流中添加几百万条未确认的消息不会改变基准测试的要点,大多数查询仍然以非常短的延迟进行处理。
几点说明:
- 在这里,我们每次迭代最多处理 10k 条消息,这意味着COUNT参数XREADGROUP设置为 10000。这会增加很多延迟,但为了让慢速消费者能够跟上消息流,这是必需的。因此,您可以预期现实世界的延迟要小得多。
- 与今天的标准相比,用于此基准测试的系统非常慢。
价格比对
1 | 华为云里面 |
pdf文件
在Golang中使用Redis Streams来实现生产者-消费者模型,你可以使用github.com/go-redis/redis/v8库。以下是一个简单的例子,展示了如何实现一个生产者和一个消费者。
首先,安装go-redis库:
1 | go get github.com/go-redis/redis/v8 |
生产者
生产者负责向Redis Stream中添加消息。下面是一个简单的生产者实现:
1 | package main |
消费者
消费者负责从Redis Stream中读取消息并处理。下面是一个简单的消费者实现:
1 | package main |
运行程序
确保你的Redis服务器正在运行,然后分别运行生产者和消费者:
1 | go run producer.go |
解释
- 生产者:每400毫秒向Redis Stream中添加一条消息。
- 消费者:从Redis Stream中读取消息,并模拟处理每条消息需要1秒钟。
这个简单的例子展示了如何使用Golang与Redis Streams来实现一个基本的生产者-消费者模型。根据你的需求,你可以进一步扩展和优化这个模型。
读取第一条和最后一条记录
1 | XRANGE XGenius:warningStream - 0 |
引用
- [1] Redis-Streams
- [2] Redis-Cluster-Streams
- [3] Redis-Streams-wrong