概述
作为Effective C++姊妹篇,这本书也是需要刷一遍的,一共35条建议。本书成书1996年,前言里面描述,其实1990-1992当时C++就已经很火爆了,大家都想着去了解这个语言(这本书写于)。
看侯杰的版本的导读篇里面的原文:
广博如四库全书者有之(The C++ Programming Language、C++ Primer),深奥如重山复水者有之(The Annotated C++ Reference Manual, Inside the C++ Object Model),细说历史者有之(The Design and Evolution of C++, Ruminations on C++),独沽一味者有之(Polymorphism in C++, Genericity in C++),独树一帜者有之(Design Patterns,Large Scale C++ Software Design, C++ FAQs),程式库大全有之(The C++ Standard Library),另辟蹊径者有之(Generic Programming and the STL),工程经验之累积亦有之(Effective C++, More Effective C++, Exceptional C++)。
这其中,「工程经验之累积」对已具 C++ 相当基础的程式员而言,有著致命的吸引力与立竿见影的帮助。Scott Meyers 的 Effective C++ 和 More Effective C++ 是此类佼佼,Herb Sutter 的 Exceptional C++ 则是後起之秀。
这类书籍的一个共通特色是轻薄短小,并且高密度地纳入作者浸淫於 C++/OOP 领域多年而广泛的经验。它们不但开展读者的视野,也为读者提供各种 C++/OOP 常见问题或易犯错误的解决模型。
导读
一旦语言进入成熟期,而我们对它的使用经验也愈来愈多,我们所需要的资讯也就随之改变。1990 年人们想知道 C++ 是什么东西。到了 1992 年,他们想知道如何运用它。如今C++ 程式员问的问题更高级:我如何能够设计出适应未来需求的软体?我如何能够改善程式码的效率而不折损正确性和易用性?我如何能够实作出语言未能直接支援的精巧机能?
本书内容分为 35 个条款。每个条款都在特定主题上精简摘要出 C++ 程式设计社群所累积的智慧。大部份条款以准则的型式呈现,附随的说明则阐述这条准则为什么存在,如果不遵循会发生什么後果,以及什么情况下可以合理违反该准则。所有条款被我分为数大类。某些条款关心特定的语言性质,特别是你可能罕有使用经验的一些新性质。
例如条款 915 专注於 exceptions(就像 Tom Cargill, Jack Reeves, Herb Sutter 所发表的那些杂志文章一样)。31 描述如何限制物件的个数或诞生地点,如何根据一个以上的物件型别产生出类似虚拟函式的东西,如何产生 smart pointers 等等。其他条款解决更广泛的题目。
其他条款解释如何结合语言的不同特性以达成更高阶目标。例如条款 25
条款 16~24 专注於效率上的议题。
不论哪一条款,提供的都是与其主题相关且意义重大的作法。在 More Effective C++一书中你将学习到如何更实效更精锐地使用 C++。
1. 基础议题
Item M1: 指针与引用的区别
因此如果你使用一个变量并让它指向一个对象,但是该变量在某些时候也可能不指向任何对象,这时你应该把变量声明为指针,因为这样你可以赋空值给该变量。相反,如果变量肯定指向一个对象,例如你的设计不允许变量为空,这时你就可以把变量声明为引用。
指针与引用的另一个重要的不同是指针可以被重新赋值以指向另一个不同的对象。但是
引用则总是指向在初始化时被指定的对象,以后不能改变。
Item M2:尽量使用C++风格的类型转换
C++风格的类型转换
1 | static_cast const_cast dynamic_cast reinterpret_cast |
static_cast转换类似C语言的转换。
const_cast转换能去除之前附上的const属性。
dynamic_cast将会沿着继承关系向下安全转换,如果非此类型将会传出一个空指针。
reinterpret_cast 使用这个操作符的类型转换,其的转换结果几乎都是执行期定义 ( implementation-defined )。因此,使用reinterpret_casts 的代码很难移植。
最普通的用途就是在函数指针类型之间进行转换。
Item M3: 不要对数组使用多态
1 | class BST { ... }; |
Item M4:避免无用的缺省构造函数
如果某个类实在没有办法去做默认构造函数,需要用下面的方法来解开。
1 | class EquipmentPiece { |
2. 运算符
Item M5:谨慎定义类型转换函数
隐式类型转换运算符
1 | class Rational { |
构造函数用 explicit 声明,如果这样做,编译器会拒绝为了隐式类型转换而调用构造函数。
Item M6:自增(increment)、自减(decrement)操作符前缀形式与后缀形式的区别
80年代的时候,没有区分++/–的前缀、后缀两种的差别。后面90年代的时候才引入了这两种写法。
前缀形式有时叫做“增加然后取回”,后缀形式叫做“取回然后增加”。
为啥后缀方式需要返回const,其实就是先将老位置的值存储一份,然后再去调整当前值的位置。
如果对于性能有一些敏感,可以考虑使用前缀加法,这样的函数没有临时变量缓存。
可以回答一下为啥vector,map里面的迭代器++方法能返回内容。
1 | class UPInt { // "unlimited precision int" |
Item M7:不要重载“&&”,“||”, 或“,”
基础知识:(短路求值法)布尔变量在if语句里面如果是&&条件,将会按照顺序如果失败就回暂停。
1 | int rangeCheck(int index) |
这种思维被反复的灌输给程序员,所以我们要避免这种惯性的思维给大家带来麻烦。举个例子下面是重载操作符的代码真实运行的情况。
1 | if (expression1 && expression2) ... |
正如显示的,存在一些限制,你不能重载下面的操作符:
1 | . .* :: ?: |
能重载的:
1 | operator new operator delete |
Item M8:理解各种不同含义的new和delete
new操作符(new operator)和new操作(operator new)的区别。
1 | string *ps = new string("Memory Management"); |
这种是new操作符,是类似于系统内置的sizeof,包含两个步骤:
- 分配raw的内存块;
- 将内存块去调用构造函数初始化对象;
我们能提供的new操作符只能工作在第一步。编写这个函数的意图也是为了接管分配的权限。
1 | void * operator new(size_t size); |
placement new
1 | class Widget { |
3. 异常
C 程序员能够仅通过 setjmp 和 longjmp 来完成与异常处理相似的功能。但是当 longjmp在 C++中使用时,它存在一些缺陷,当它调整堆栈时不能对局部对象调用析构函数。(WQ 加注,VC++能保证这一点,但不要依赖这一点。)而大多数 C++程序员依赖于这些析构函数的调用,所以 setjmp 和 longjmp 不能够替换异常处理。如果你需要一个方法,能够通知不可被忽略的异常状态,并且搜索栈空间(searching the stack)以便找到异常处理代码时,你还得确保局部对象的析构函数必须被调用,这时你就需要使用 C++的异常处理。
Item M9:使用析构函数防止资源泄漏
1 | void processAdoptions(istream& dataSource) |
在这里就引入了auto_ptr类,如果一个指针和这块内存的生存周期有强的依赖关系,推荐使用这种方式来管理这种指针,可以处理很多出问题的情况。
Item M10:在构造函数中防止资源泄漏
1 | void testBookEntryClass() |
作者再次推荐此处应该使用auto_ptr来管理这些指针,此书1996年,当时的C++专家就开始谈论exception带来的一系列问题,并且推荐智能指针的使用,避免程序出现各种问题。
Item M11:禁止异常信息(exceptions)传递到析构函数外
此条目和《Effective C++ Item 8 别让异常逃离析构函数》有相同的意思。
我们知道禁止异常传递到析构函数外有两个原因:
第一能够在异常转递的堆栈辗转开解(stack-unwinding)的过程中,防止 terminate 被调用。
调用析构函数时异常可能处于激活状态也可能没有处于激活状态。遗憾的是没有办法在析构函数内部区分出这两种情况。因此在写析构函数时你必须保守地假设有异常被激活。因为如果在一个异常被激活的同时,析构函数也抛出异常,并导致程序控制权转移到析构函数外,C++将调用 terminate 函数。
第二它能帮助确保析构函数总能完成我们希望它做的所有事情。(如果你仍旧不很信服我所说的理由,可以去看Herb Sutter 的文章 Exception-Safe Generic Containers ,特别是“Destructors That Throw and Why They’re Evil”这段)。
Item M12:理解“抛出一个异常”与“传递一个参数”或“调用一个虚函数”间的差异
传递函数参数时可以通过:传值、传递引用和传递指针。当使用抛异常,到捕获异常的时候也能使用这三种方式来定义。区别在于函数调用还会回去,异常、捕获是不会返回回去(因为异常之后的代码端其实都已经不会执行了,这段代码的scope完),所以无论你是否使用了引用方式,其实都做了一次构造。
1 | // 这种方式会有两次分配 |
如果子类抛出异常的时,转换成父类抛出,将会去掉子类的特性。父类能catch子类的throw。如果父类已经在前面catch了,在下面写子类的catch将永远不会执行。应该将子类的catch写到父类的前面。
Item M13:通过引用(reference)捕获异常
如果你通过引用捕获异常(catch by reference),你就能避开上述所有问题,不会为是否删除异常对象而烦恼;能够避开 slicing 异常对象;能够捕获标准异常类型;减少异常对象需要被拷贝的数目。所以你还在等什么?通过引用捕获异常吧(Catch exceptions by reference)!
如果需要使用 exception* ex方式,需要使用static exception。变量就没有释放。
也可以自己本地去 new 一个exception,catch之后用完之后自己去做delete。
还不如直接构造一个对象抛出,catch的时候使用 exception& ex方式。
Item M14:审慎使用异常规格(exception specifications)
1 | // 可以抛出任意异常 |
在C++11中如果noexcept修饰的函数抛出了异常,编译器可以选择直接调用std::terminate()函数来终止程序的运行
可以通过在定义函数的时候,限定其无法抛出异常。这样注册函数指针的时候就会出现编译报错。
这种对于是否能抛出异常,抛出什么样的异常的定义就叫做“异常规格”检查。
如果代码中存在operator new和operator new[]就有可能出现bad_alloc错误。所以有new的函数调用,就要做bad_alloc的准备。
防范于未然才是比较好的。unexpected异常被抛出的时候,程序就有可能直接被终止。所以需要自己平时就管理好这些异常。
我们可以通过自定义一个类来替换掉系统默认的unexpected函数。通过set_unexpected函数来指定。这样就能防止程序被终止。
还有一种方法就是通过对有危险的函数做try catch(…)将全部的异常可能性都catch,防止出现问题。
Item M15:了解异常处理的系统开销
默认的情况下,异常处理是被开启的,如果全部的C+++代码都是自己实现,而且没有涉及到任何的异常抛出的情况。这样可以开启不支持异常处理的方式进行编译,这样可以减少程序的尺寸和提高速度。但是现在C++库很少不支持异常,只要还有一个库还支持,那就需要开启。
异常处理开销来源于try模块。程序的尺寸和运行速度会增加5%~10%。如果抛出异常的情况下,可能消耗会更加大。大多数情况下都不会抛出异常。当抛出异常从函数力返回可能会慢三个数量级。
为了使你的异常开销变小:尽量采用不支持异常的方式来编译程序;将try块代码压缩成不需要得使用的区间;使用异常规格限定你需要使用的地方,只有在需要异常的时候才会抛出。
4. 效率
糟糕的设计和马虎的编程将会造成程序大小太大,运行需要更多内存,更多时间。
高效的程序首先是算法要比较过硬。如果太烂的实现可以比喻成一个二流的观光地。
阐述效率问题。
第一是从语言独立的角度,关注那些任何语言里面都能使用的东西。其实就是通用算法数据结构的基础要做的很好。
第二是关注C++语言本身。思路没有问题之后,需要用C++更好的表达你的思路。例如:平凡的构造和释放大量的对象。
Item M16:牢记 80-20 准则(80-20 rule)
80-20准则说的就是20%的代码使用了80%的资源。
发现程序里面的消耗问题,不能只靠直觉、经验、算命纸牌等荒唐的东西。最好的方式是使用profiler告诉你程序的各个部分都消耗了多少时间。
Item M17:考虑使用lazy evaluation(懒惰计算法)
这个优化思路是能应用在其他的语言。
引用计数
1 | class String{}; |
除非你确实需要,不去为任何东西制作拷贝。
区别对待读取和写入
1 | String s = "Homer's Iliad"; // 假设是一个 |
我们应能够区别对待读调用和写调用,因为读取 reference-counted string 是很容
易的,而写入这个 string 则需要在写入前对该 string 值制作一个新拷贝。
Lazy Fetching(懒惰提取)
一个很大的对象,从数据库中加载起来。应该是先创建一个大对象壳子,然后在使用的时候再去将其内存初始化。这些成员变量使用mutable来修饰。这样在任何函数(包含const)里面都能去修改这个成员变量。
也可以通过const_cast,去除const成员函数中的this的const修饰。然后完成对于成员变量的修改。
Lazy Expression Evaluation(懒惰表达式计算)
举例子,两个100*100矩阵,如果需要计算乘法,如果一次性将期内存分配出来,并且计算出来,肯定会非常卡。当用的时候,我们再开始去计算其的值。APL—1960发展起来的语言,能够进行矩阵的交互式计算。当时计算机的能力没有现在的微波炉芯片高,它能胜任矩阵的加、乘,甚至能够快速的与大矩阵相除。其实就是尽量推迟计算的时机。
Lazy evaluation 懒惰的策略;
eager evaluation 热情的策略;
总结:
- 减少无用的拷贝;
- 通过operator[]区分出读操作,降低消耗;
- 避免不需要的数据库读取操作;
- 避免不需要的数字操作;
- 避免自己瞎猜,最好还是通过profiler调查某个模块是不是太慢了,如果存在就开始改造。
Item M18:分期摊还期望的计算
over-eager evaluation(过度热情计算法)。
有些时候需要让程序变得更加的积极。比如计算大量数据的平均值、最小值、最大值。在每个数字加入进来的时候才会变化。所以可以考虑在加入的时候将这个值计算出来,防止调取的时候,反复计算。
最简单方法就是在这里增加一个caching层。
在使用map的迭代器的时候两种写法的差别。
1 | (*it).second; |
为了遵循STL规则,it是个对象,不是指针,所以不能保证->被正确应用到它上面。所以(*it).second虽然反隋,但是保证能运行。
Item M19:理解临时对象的来源
程序员聊天时候,说的存在一段时间的变量被称为临时变量,在c++里面被称为函数的局部变量。C++真正的临时变量是看不见的,且不在堆上分配(non-heap)的临时对象。
产生这种未命名的对象通常有两种情况:为了是函数成功调用而进行的隐式类型转换和函数返回值对象时。
传递的参数类型和函数参数表类型不匹配时,触发了隐式类型转换,将会直接触发构造生成匹配类型的对象。这种情况出现在值传递、常量引用传递的情况下,非常量引用传递就不会触发。
函数返回值如果写成了const Number operator+(const Number& lhs, const Number& rhs);这样也会有构造函数析构函数。
Item M20:协助完成返回值优化
1 | // 一种不合理的避免返回对象的方法 |
在C++里面有一种技术叫做(RVO)什么时候应当依靠返回值优化(RVO)。学习了C++11之后,有可能程序员会想使用std::move来将一个object变成一个右值传递回去。刚刚那篇文章分析了这样写的问题。反而不能使用std::Move来做,而是使用
RVO反而会速度快很多。
1 | // 第一种写法 |
Item M21:通过重载避免隐式类型转换
有关为什么返回值是 const 的解释,参见 Effective C++ 条款 21。
1 | const UPInt operator+(const UPInt& lhs, const UPInt& rhs); |
不要过度优化,记住80-20原则,对一个东西的优化,需要拿的出来比较靠得住的依据。
Item M22:考虑用运算符的赋值形式(op=)取代其单独形式(op)
举例子
1 | // 大多数程序员认为如果他们能这样写代码: |
其实对于c++来说是存在不同的操作符重载的。operator+、operator=和 operator+=之间没有任何关系。加法操作符和赋值操作符。+=只需要一次性操作就好了。可以考虑直接使用operator+=实现operator+,这里面构造一个临时的变量。
与效率上做出折衷选择。也就是说,客户端可以决定是这样编写:
1 | Rational a, b, c, d, result; |
Item M23:考虑变更程序库
介绍了iostream和stdio程序库的差别。c++库能支持类型安全,而且能扩展。stdio库效率高,可能没有安全检测,产生的文件也小,执行速度快。可以通过编写benchmark来对比两个库的速度差异。不过还需要自己动脑筋模拟客户的操作来编写一个benchmark来真实测试一次消耗情况。
优势它仅仅快一些(大约 20%),有时则快很多(接近 200%),但是我从来没有遇到过一种 iostream 的实现和与其相对应的 stdio 的实现运行速度一样快。
Item M24:理解虚拟函数、多继承、虚基类和RTTI所需的代价
每种C++编译器都会实现语言中的特新,而且程序员都不用去关心其细节。虚函数和对象大小和成员函数执行效率有关系,这块知识点需要多掌握一些。
调用一个虚拟函数的时候,大多数编译器将会使用virtual table、virtual table pointers来实现。
virtual table通常是函数指针数组(有些编译器是使用的链表来处理)。非虚函数将不会放入这个列表中。每个类只需要一个vtbl拷贝。
C2继承于C1,在C2中未实现的C1虚方法,将会在C2 virtual table里面保存一份C1中实现的虚方法;如果在C2重新定义了,将会直接使用C2的虚方法。


总结:虚方法其实在每个子类里的virtual table都会存储一份函数指针。
编译器实现存在两种路线:
- 对于提供集成开发环境的厂商,为每个可能需要使用vtbl的object文件生成一个vtbl拷贝。linker程序去去重拷贝。
- 使用启发式算法决定哪个object文件应该包含vtbl。要在一个object文件中生成一个类的vtbl,要求该object文件包含该类的第一个非内联、非纯虚拟函数(non-inline non-pure virtual function)。
如果你过分喜欢声明虚函数为内联函数(参见 Effective C++ 条款 33),可能会造成启发式算法失败,在大型系统里面会造成同一个类的成百上千的vtbl拷贝。要避免virtual 变成一个inline函数。
用图例来说明内存分配的样子。
含有虚拟函数的对象内存布局为:
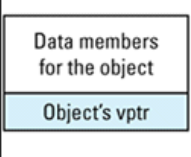
下面有个指向vptr的指针。
vtbl数据结构是按照Class来分配的,当实例化出来object之后,通过vptr将指针指向对应的vtbl里面。
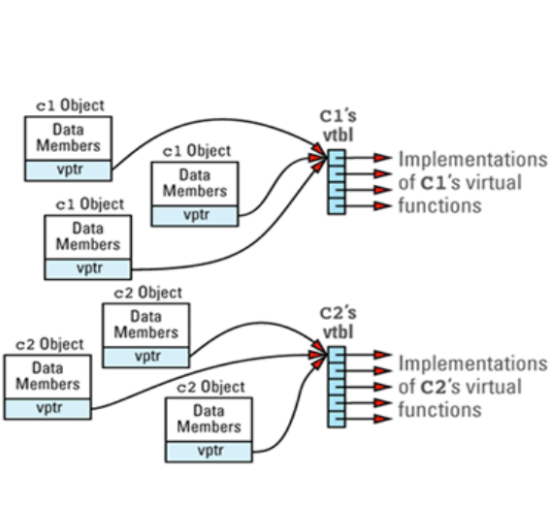
实际上调用虚函数的效率和调用函数指针一样。虚拟函数本身通常不是性能的瓶颈。
在多重继承的时候会在vptr里面,为每一个基类都分配了vptr。自己独立的生成过一个vtbl,而且为每个基类都生成了特殊的vtbl。因此每个对象,每个类的空间都要占的更多。
运行时类型识别(RTTI),有地方存储了一个type_info的对象,存储是放入了class的vtbl的最前面,而且vtbl这个数据结构,不是到处都在复制,而是一种公用的数据结构。所以这块的开销不会造成困扰。
下面这个表各是对虚函数、多继承、虚基类以及 RTTI 所需主要代价的总结:
| Faature | Increases Size of Objects | Increases Per-Class Data | Reduces Inlining |
|---|---|---|---|
| Virtual Functions | ☑ | ☑ | ☑ |
| Multiple Inheritance | ☑ | ☑ | ❌ |
| Virtaul Base Classes | Often | Sometimes | ❌ |
| RTTI | ❌ | ☑ | ❌ |
5. 技巧
本章主要是介绍一些编程的技巧。在日复一日的软件开发工作时,下面这些信息都将使你受益。
Item M25:将构造函数和非成员函数虚拟化
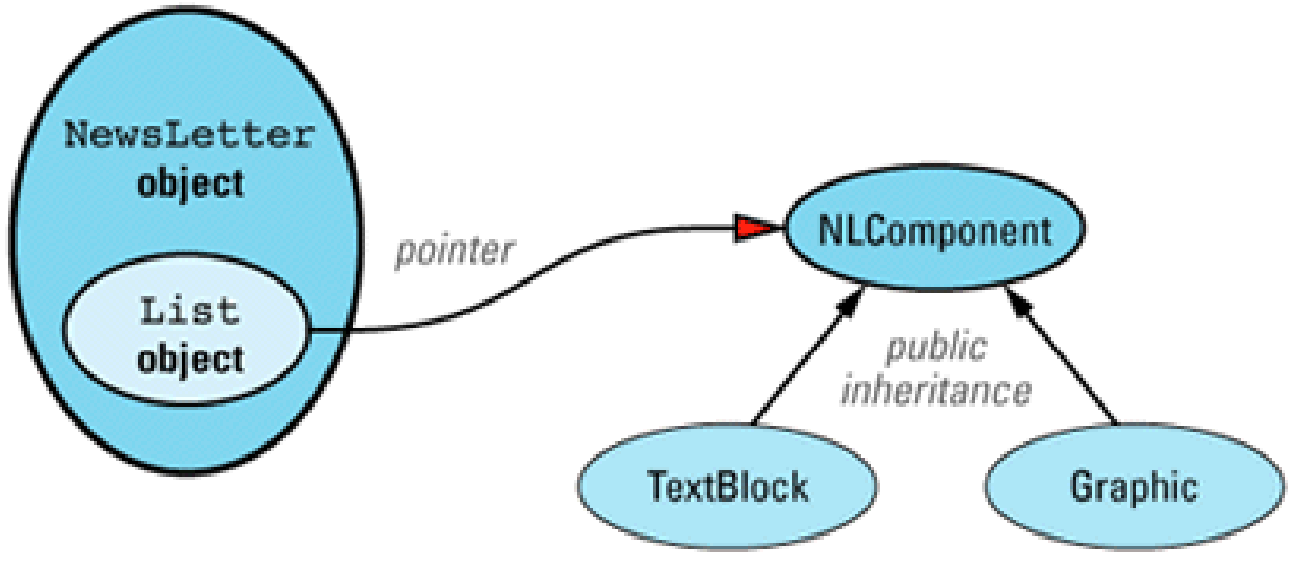
1 | class NLComponent { |
Item M26:限制某个类所能产生的对象数量
可以使用namespace来将函数的作用域限制起来。
将构造函数设置成private防止外部多次构造,局限在自己的friend function里面构造。
在构造、析构函数里面加入计数器,防止其过多次的构造。
最终抽象了一个模板计数基类来处理这些重复代码。当出现了多次分配,将会抛出TooManyObjects异常。
Item M27:要求或禁止在堆中产生对象
两种情形:
- 嵌入式环境中,堆空间很珍贵,所以可能不允许在堆上申请任何的对象;
- 不允许在堆上申请任何对象,防止内存泄漏;
不允许在堆里面申请对象;
1 | class UPNumber { |
这种方法也禁止了继承和包容(包容其实就是在其他类里面直接定义对象),因为他们的构造、析构函数被设置成了private方式了。
将其设置成protected方式,就能兼容继承问题。
判断一个对象是否在堆中
文中尝试了通过修改代码来将一个对象是否为堆上分配做标记,operator new操作符来做手脚,其实时徒劳的。比如 new MyClass[20];此语句将会只有第一个元素调用过,当第二个元素调用的时候,将会抛出异常,因为全部的20个对象都是使用了相同的标记位,而分配只做了一次。
堆、栈空间分配示意图:
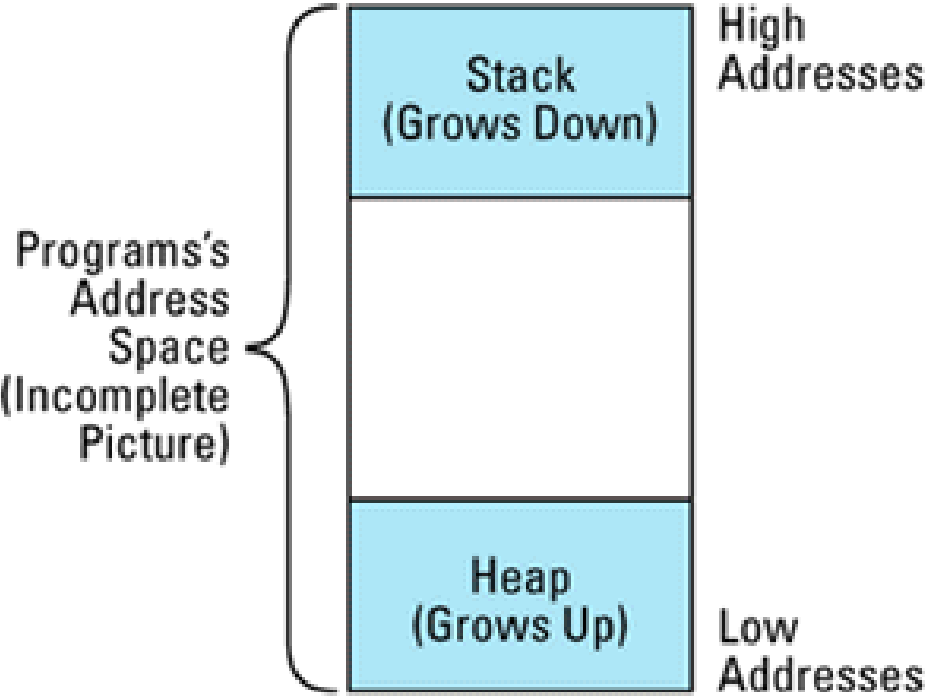
可能会动一些脑子去定义一个stack上的变量取地址,然后对比,其实也是会存在问题的。因为我们需要考虑static变量的地址。
最终还是通过重载new operator函数,将全部分配的内存地址都保存起来,当需要判断的时候,只需要通过查找这个内存块的地址是不是在之前分配过就好了。
禁止堆对象
如何制作一个无法在堆上分配的对象,其实这个处理就是将operator new函数设置成private方式。
Item M28:智能(smart)指针
智能指针实现了类似内建指针的功能。启用之后的好处:
- 构造和析构。创建会默认设置成0,而且某些智能指针会负责自动删除掉指向对象,防止资源泄露。
老版本的auto_ptr其实就是unqiue_ptr,如果赋值应该要考虑将所有权交换掉。
拷贝和赋值。有些智能指针是拷贝所指的对象(deep copy),有些事拷贝指针,有些指针不允许赋值。
defrefrencing。